1장. 한눈에 보는 머신러닝
1장. 한눈에 보는 머신러닝
1.1 머신러닝이란?
- 머신러닝: 데이터에서 학습하도록 컴퓨터를 프로그래밍하는 과학.
용어
- 훈련 세트: 시스템이 학습하는 데 사용하는 샘플
- 훈련 사례(or 샘플): 각각의 훈련 데이터
- 모델: 머신러닝 시스템에서 학습하고 예측을 만드는 부분
- 정확도: 성능 측정
1.2 왜 머신러닝을 사용하나요?
- 프로그램이 훨씬 짧아진다.
- 유지보수가 쉽다.
- 정확도가 높다.
- 자동으로 변화에 적응한다.
- 전통적인 방식으로는 해결할 수 없는 분야를 해결함. (ex. 음성 인식)
- 머신러닝을 통해 배울 수 있다.
용어
- 데이터 마이닝: 대용량의 데이터를 분석하여 숨겨진 패턴을 발견하는 것.
- 시맨틱 분할: 딥러닝(DL) 알고리즘을 사용하여 픽셀에 클래스 레이블을 할당하는 컴퓨터 비전 작업.
1.3 머신러닝 시스템의 종류
1.3.1 훈련 지도 방식
⭐어떻게 훈련되는가?
지도 학습
- 알고리즘에 주입하는 훈련 데이터에 레이블이라는 원하는 답이 포함됨.
- EX) 분류, 회귀(특성을 사용해 타깃 수치를 예측하는 것), 로지스틱 회귀(클래스에 속할 확률 출력)
비지도 학습
- 훈련 데이터에 레이블X
- EX) 군집 알고리즘, 계층 군집 알고리즘(각 그룹을 더 작은 그룹으로 세분화할 수 있음 / 분할 군집 or 병합 군집), 시각화 알고리즘(레이블이 없는 대규모의 고차원 데이터를 넣으면 도식화가 가능한 2D나 3D 표현을 만들어줌 / t-SNE), 차원 축소(특성 추출), 이상치 탐지, 특이치 탐지, 연관 규칙 학습
준지도 학습
- 레이블이 일부만 있는 데이터
자기 지도 학습
- 레이블이 전혀 없는 데이터셋에서 레이블이 완전히 부여된 데이터셋을 생성하는 것.
전이 학습
- 한 작업에서 다른 작업으로 지식을 전달하는 것.
강화 학습
- 에이전트: 학습하는 시스템
- 보상: 환경을 관찰해서 행동을 실행하고 그 결과로 받는 것(부정적인 보상도 받음 - 벌점)
- 정책: 주어진 상황에서 에이전트가 어떤 행동을 선택해야 할지 정의
=> 보상에 따라 정책이라고 불리는 최상의 전략을 스스로 학습.
1.3.2 배치 학습과 온라인 학습
⭐입력 데이터의 스트림으로부터 점진적으로 학습할 수 있는지 여부에 따라 구분
배치 학습
시스템이 점진적으로 학습 불가능. 가용한 데이터를 모두 사용해 훈련시켜야함.
=> 매번 새로 학습할때 마다 “예전 데이터 + 새로운 데이터”의 전체 데이터셋을 학습시켜야함.- 오프라인 학습: 학습한 것만을 적용시킴. 시스템에 적용하면 더 이상의 학습X
- 모델 부패(데이터 드리프트): 모델의 성능은 시간이 지나면서 천천히 감소.
온라인 학습
- 데이터를 순차적으로 한 개씩 또는 미니배치라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킴.
- 온라인 학습에서는 모델을 훈련하고 제품에 론칭한 뒤에도 새로운 데이터가 들어오면 계속 학습함.
- 외부 메모리 학습: 컴퓨터 한 대의 메인 메모리에 들어갈 수 없는 아주 큰 데이터셋에서 모델을 훈련하는 것.
- 점진적 학습.
- 오프라인으로 실행(실시간 시스템에서 수행되는 것이 아님.)
- 온라인 학습은 외부 메모리 학습을 포함하지만, 모든 외부 메모리 학습이 온라인 학습인 것은 아님.
- 학습률: 변화하는 데이터에 얼마나 빠르게 적응할 것인지.
1.3.3 사례 기반 학습과 모델 기반 학습
⭐어떻게 일반화 되는가?
사례 기반 학습(기억)
- 단순히 기억하는 것! (ex. 스팸메일과 동일한 메일 구분)
- 발전된것이 유사도 측정! (ex. 스팸메일과 동일한 단어의 출연 횟수)
=> 기억으로 학습하고, 유사도 측정을 사용해 일반화!
모델 기반 학습
- 샘플들의 모델을 만들어 예측에 사용하는 것.
- 모델 선택 (ex. 선형 모델 선택)
- 모델을 사용하기 전에 적절한 모델 파라미터 정의.
- 효용 함수(적합도 함수): 모델이 얼마나 좋은지 측정.
- 비용 함수: 모델이 얼마나 나쁜지 측정.
=> 알고리즘을 통해 적절한 파라미터 찾는 과정이 훈련
1.4 머신러닝의 주요 도전 과제
1.4.1 충분하지 않은 양의 훈련 데이터
- 데이터의 양도 중요하지만, 데이터를 추가로 모으는 것이 항상 쉽거나 저렴한 일은 아니므로, 아직은 알고리즘을 무시하지 말아야 한다!
1.4.2 대표성 없는 훈련 데이터
- 샘플이 작으면 샘플링 잡읍이 생기고, 매우 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띠지 못할 수 있다.
=> 샘플링 편향
1.4.3 낮은 품질의 데이터
- 이상치, 오류, 결측치 등을 포함
1.4.4 관련 없는 특성
- 특성 공학: 훈련에 사용할 좋은 특성 찾기
- 특성 선택: 가지고 있는 특성 중에서 훈련에 가장 유용한 특성을 선택.
- 특성 추출: 특성을 결합하여 더 유용한 특성을 만듦. 앞서 본 것처럼 차원 축소 알고리즘이 도움이 될 수 O
- 데이터 수집: 새로운 데이터를 수집해 새 특성을 만듦.
1.4.5 훈련 데이터 과대적합
- 과대적합: 모델이 훈련 데이터에 너무 잘 맞아 일반성이 떨어짐.
- 과대적합을 줄이기 위해?
- 모델 단순하게 만들기
- 데이터 많이 모으기
- 데이터의 잡음 줄이기
=> 규제!
🔖규제
- ex) 기울기가 너무 커지지 않도록 규제. 자유도 1과 2 사이의 적절한 어딘가에 위치해 일반화 성능을 높일 수 있음.
- 하이퍼파라미터: (모델이 아니라)학습 알고리즘의 파라미터. 훈련 전에 미리 지정되고, 훈련하는 동안에는 상수로 남음.
- 규제 하이퍼파라미터를 크게 하면, 거의 평평한 모델이 됨.
1.4.6 훈련 데이터 과소적합
- 과소적합: 모델이 너무 단순해서, 데이터의 내재된 구조를 학습하지 못하는 것.
- 해결하려면?
- 모델 파라미터가 더 많은 강력한 모델 선택.
- 학습 알고리즘에 더 좋은 특성 제공(특성 공학)
- 모델의 제약을 줄임.
1.5 테스트와 검증
- 훈련 데이터를 훈련 세트와 검증 세트로 나누기!
- 일반화 오차(외부 샘플 오차): 새로운 샘플에 대한 오차 비율
- 테스트 세트에서 모델을 평가함으로써 이 오차에 대한 추정값을 얻음.
1.5.1 하이퍼파라미터 튜닝과 모델 선택
- 모델 평가 -> 테스트 세트 이용
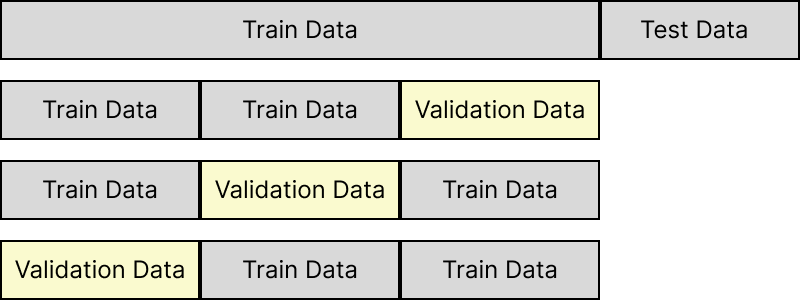
- 홀드아웃 검증: 훈련 세트의 일부를 검증 세트로 이용!
- 줄어든 훈련 세트에서 다양한 하이퍼파라미터 값을 가진 여러 모델을 훈련. 그 다음 검증 세트에서 가장 높은 성능을 내는 모델을 선택. 끝나면 검증 세트를 포함한 전체 훈련 세트에서 다시 훈련 시켜 최종 모델 만듦.
- 교차 검증: 검증 세트를 여러 개를 사용해 반복적으로 수행하는 것. 검증 세트마다 나머지 데이터에서 훈련한 모델을 해당 검증 세트에서 평가.
1.5.2 데이터 불일치
- 훈련-개발 세트: 훈련 사진의 일부를 떼어내 또 다른 세트를 만드는 것 -> 모델을 훈련 세트에서 훈련한 다음 훈련-개발 세트에서 평가. 모델이 잘 작동하지 않으면 훈련 세트에 과대적합된 것.
❗만약, 성능이 나쁘다면 데이터 불일치 때문!
⭐ Train(train + train_dev) + Validation + Test
This post is licensed under CC BY 4.0 by the author.