10.앙케트 분석을 위한 자연어 처리 테크닉 10
10.앙케트 분석을 위한 자연어 처리 테크닉 10
🔖전제조건
- survey.csv: 앙케트 결과
- 캠페인 기간(2019년 1월 ~ 4월)의 4개월 동안 모은 고객만족도 설문조사 데이터가 데이터베이스에 기록돼 있음
- 설문조사를 한 날짜, 의견, 만족도(5단 평가)의 결과가 들어 있음.
091.데이터를 불러서 파악해 보자
데이터 불러오기
1
2
3
4
import pandas as pd
survey = pd.read_csv("survey.csv")
print(len(survey))
survey.head()
결측치 확인
1
survey.isna().sum()

결측치 제거
1
2
survey = survey.dropna()
survey.isna().sum()

092.불필요한 문자를 제거하자
- 특정 문자 제거 / 정규 표현식 활용
특수문자 제거
1
2
survey["comment"] = survey["comment"].str.replace("AA", "")
survey.head()
정규 표현으로 제거
- 정규 표현식
- 문자를 일정한 규칙으로 제거할 때 이용
- 정규 표현식은 문자 등의 패턴을 표현할 수 있음
- 괄호의 패턴을 검색해서 치환할 수 있음
1
2
3
4
5
survey["comment"] = survey["comment"].str.replace("\(.+?\)", "")
# regex=True로 설정하면 str.replace()에서 첫 번째 인수를 정규 표현식으로 인식
# '\(' 와 '\)'는 ()를 의미
# .+?는 1문자 이상이라는 의미
survey.head()
093.문자 수를 세어 히스토그램으로 표시해 보자
length 칼럼 추가
1
2
survey["length"] = survey["comment"].str.len()
survey.head()
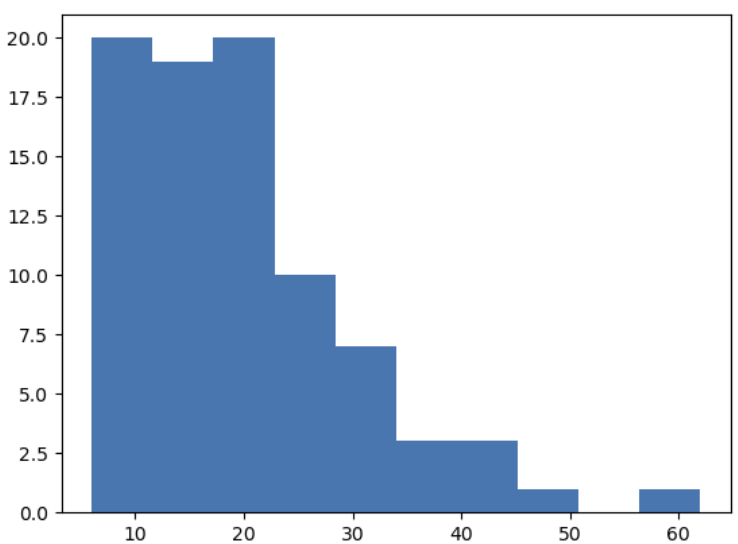
의견 길이 히스토그램
1
2
3
4
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(survey["length"])
# 공백 포함
094.형태소 분석으로 문장을 분석해 보자
- 형태소 분석: 문장을 단어로 분할하는 기술(ex.konlpy)
형태소 분석
1
2
3
4
5
from konlpy.tag import Twitter
twt = Twitter()
text = "형태소분석으로 문장을 분해해보자"
tagging = twt.pos(text)
tagging

형태소 분석을 이용한 단어 추출
1
2
3
4
5
6
7
8
words = twt.pos(text)
words_arr = []
for i in words:
if i == 'EOS': continue
# 'EOS'는 분석 결과의 끝을 의미하므로, 이를 건너뜁니다.
word_tmp = i[0]
words_arr.append(word_tmp)
words_arr

095.형태소 분석으로 문장에서 ‘동사’, ‘명사’를 추출해 보자
text = "형태소분석으로 문장을 분해해보자"
words_arr = []
parts = ["Noun", "Verb"]
words = twt.pos(text)
words_arr = []
for i in words:
if i == 'EOS' or i == '': continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
words_arr.append(word_tmp)
words_arr

096.형태소 분석으로 자주 나오는 명사를 확인해 보자
survey 데이터에서 명사 추출
1
2
3
4
5
6
7
8
9
10
11
12
13
14
all_words = []
parts = ["Noun"]
for n in range(len(survey)):
text = survey["comment"].iloc[n]
words = twt.pos(text)
words_arr = []
for i in words:
if i == "EOS" or i == "": continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
words_arr.append(word_tmp)
all_words.extend(words_arr)
print(all_words)

survey 데이터 많이 나오는 단어
1
2
3
all_words_df = pd.DataFrame({"words":all_words, "count":len(all_words)*[1]})
all_words_df = all_words_df.groupby("words").sum()
all_words_df.sort_values("count",ascending=False).head()

097.관계없는 단어를 제거해 보자
제외 키워드 제거
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
stop_words = ["더","수","좀"]
all_words = []
parts = ["Noun"]
for n in range(len(survey)):
text = survey["comment"].iloc[n]
words = twt.pos(text)
words_arr = []
for i in words:
if i == "EOS" or i == "": continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
if word_tmp in stop_words:continue
words_arr.append(word_tmp)
all_words.extend(words_arr)
print(all_words)

제외 단어 제거 후 남은 빈출 단어
1
2
3
all_words_df = pd.DataFrame({"words":all_words, "count":len(all_words)*[1]})
all_words_df = all_words_df.groupby("words").sum()
all_words_df.sort_values("count",ascending=False).head()

098.고객만족도와 자주 나오는 단어의 관계를 살펴보자
단어와 고객만족도 추출
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
stop_words = ["더","수","좀"]
parts = ["Noun"]
all_words = []
satisfaction = []
for n in range(len(survey)):
text = survey["comment"].iloc[n]
words = twt.pos(text)
words_arr = []
for i in words:
if i == "EOS" or i == "": continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
if word_tmp in stop_words:continue
words_arr.append(word_tmp)
satisfaction.append(survey["satisfaction"].iloc[n])
all_words.extend(words_arr)
all_words_df = pd.DataFrame({"words":all_words, "satisfaction":satisfaction, "count":len(all_words)*[1]})
all_words_df.head()
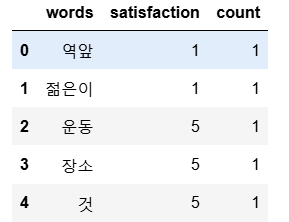
고객만족도 계산
1
2
3
4
words_satisfaction = all_words_df.groupby("words").mean()["satisfaction"]
words_count = all_words_df.groupby("words").sum()["count"]
words_df = pd.concat([words_satisfaction, words_count], axis=1)
words_df.head()
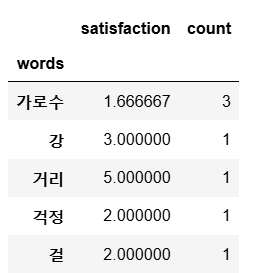
고객만족도가 높은/낮은 단어
- 소수 의견 말고 count가 3 이상인 데이터만!
1
2
words_df = words_df.loc[words_df["count"]>=3]
words_df.sort_values("satisfaction", ascending=False).head()
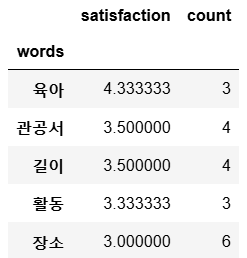
1
words_df.sort_values("satisfaction").head()
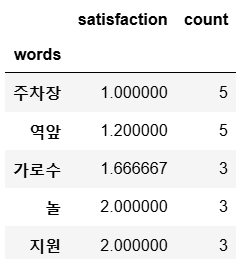
099.의견을 특징으로 표현해 보자
의견 특징 작성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
parts = ["Noun"]
all_words_df = pd.DataFrame()
satisfaction = []
for n in range(len(survey)):
text = survey["comment"].iloc[n]
words = twt.pos(text)
words_df = pd.DataFrame()
for i in words:
if i == "EOS" or i == "": continue
word_tmp = i[0]
part = i[1]
if not (part in parts):continue
words_df[word_tmp] = [1]
all_words_df = pd.concat([all_words_df, words_df] ,ignore_index=True)
all_words_df.head()

- 의견에 ㅗ함된 단어는 1 / 그 외에는 결측치가 대입
의견의 특징 결측치 처리
1
2
all_words_df = all_words_df.fillna(0)
all_words_df.head()

100.비슷한 설문지를 찾아보자
타깃 의견 추출
1
2
3
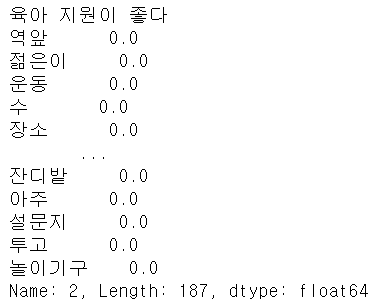
print(survey["comment"].iloc[2])
target_text = all_words_df.iloc[2]
print(target_text)
유사도 계산
1
2
3
4
5
6
7
8
9
import numpy as np
cos_sim = []
for i in range(len(all_words_df)):
cos_text = all_words_df.iloc[i]
cos = np.dot(target_text, cos_text) / (np.linalg.norm(target_text) * np.linalg.norm(cos_text))
# np.linalg.norm: 백터의 길이 계산
cos_sim.append(cos)
all_words_df["cos_sim"] = cos_sim
all_words_df.sort_values("cos_sim",ascending=False).head()
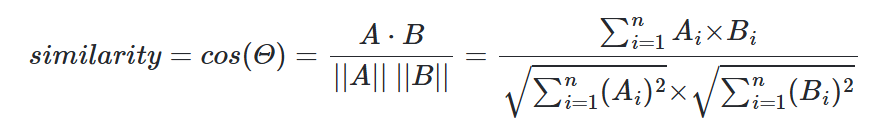

유사 의견 출력
1
2
3
print(survey["comment"].iloc[2])
print(survey["comment"].iloc[15])
print(survey["comment"].iloc[24])

This post is licensed under CC BY 4.0 by the author.