2장. 머신러로젝트 처음부터 끝까지
- 큰 그림 보기.
- 데이터 구하기
- 데이터로부터 인사이트를 얻기 위해 탐색하고 시각화하기.
- 머신러닝 알고리즘을 위해 데이터를 준비하기.
- 모델을 선택하고 훈련하기.
- 모델을 미세 튜닝하기.
- 솔루션 제시하기.
- 시스템을 론칭하고, 모니터링하고, 유지 보수하기.
2.1 실제 데이터로 작업하기
- StatLib 저장소에 있는 주택 가격 데이터셋!
2.2 큰 그림 보기
- 캘리포니아 인구 조사 데이터: (캘리포니아의 블록 그룹 마다) 인구, 중간 소득, 중간 주택 가격 등을 포함.
2.2.1 문제 정의
❓ “비지니스의 목적이 정확히 무엇인가”
💡파이프라인이란?
데이터 처리 컴포넌트들이 연속되어 있는 것. 각 컴포넌트는 많은 데이터를 추출해 처리하고 그 결과를 다른 데이터 저장소(컴포넌트 사이의 인터페이스)로 보냅니다. 그러면 다음 컴포넌트가 그 데이터를 추출해 자신의 출력 결과를 만듭니다.
❓ 어떻게 해결할 건인가?
- 지도 학습 -> 레이블된 훈련 샘플이 있기 때문.
- 그 중에서도 회귀! (다중 회귀 이자 단변량 회귀)
- 배치 학습 -> 데이터에 연속적인 흐름이 없고 빠르게 변하는 데이터에 적응하지 않아도 되고, 데이터가 메모리에 들어갈 만큼 충분히 작기 때문.
2.2.2 성능 측정 지표 선택
- 평균 제곱근 오차(RMSE)
- Euclidean Norm 이용 (L2 norm)
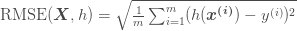
- 평균 절대 오차(MAE): 이상치로 보이는 구역이 많을 시
- Manhattan norm 이용 (L1 norm)
💡norm
norm의 지수가 클수록 큰 값의 원소에 치우치며 작은 값은 무시된다. 그래서 RMSE가 MAE보다 조금 더 이상치에 민감하다. 하지만, 이상치가 매우 드물면 RMSE가 잘 맞는다.
2.2.3 가정 검사
❗주의
- 하위 시스템에서 값을 (‘저렴’, ‘보통’, ‘고가’ 같은) 카테고리로 바꾸고 가격 대신 카테고리를 이용한다면, 정확한 가격을 구하는게 중요하지 않게 되고 이러한 문제는 회귀가 아니라 분류다.
=> 잘 고려해보기!!
2.3 데이터 가져오기
2.3.5 데이터 다운로드
- housing.csv를 압축한 housing.tgz 파일.
- 데이터를 수동으로 다운X -> 코드로! (스케쥴링하여 주기적으로 실행 가능!)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from pathlib import Path
import pandas as pd
import tarfile
import urllib.request
def load_housing_data():
tarball_path = Path("datasets/housing.tgz")
if not tarball_path.is_file():
Path("datasets").mkdir(parents=True, exist_ok=True)
url = "https://github.com/ageron/data/raw/main/housing.tgz"
urllib.request.urlretrieve(url, tarball_path)
with tarfile.open(tarball_path) as housing_tarball:
housing_tarball.extractall(path="datasets")
return pd.read_csv(Path("datasets/housing/housing.csv"))
housing = load_housing_data()
2.3.6 데이터 구조 훑어보기
- .head() 이용
- 각 행은 하나의 구역 나타냄.
- .info() 이용
- 데이터에 대한 간략한 설명 보여줌.(전체 행 수, 각 특성의 데이터 타입과 널이 아닌 값의 개수 확인)
- .value_counts(): 변수별 갯수
- ex) housing[‘ocean_proximity’].value_counts()
- .describe(): 숫자형 특성의 요약 정보 보여줌
- null 값은 제외
- count, max, min, std, 백분위수 등
- .hist(bins= , figsize = ( , )): 숫자형 특성을 히스토그램으로 그려보기
- ex) housing.hist(bins=50, figsize=(12,8))
2.3.7 테스트 세트 만들기
데이터 스누핑 편향: 모델을 학습시킨 Data set으로 일반화 오차를 추정하면 매우 낙관적인 추정이 나옴.
테스트 셋은 일반적으로 20%정도 떼어놓으면 됨.
1
2
3
4
5
6
7
8
9
import numpy as np
def shuffle_and_split_data(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
# index를 랜덤으로 섞고, 정렬해서 반환.
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
❗이 코드를 계속 실행하면 다른 테스트 세트가 형성됨!
- 처음 실행에서 테스트 세트를 저장하고, 다음번 실행에서 이를 불러들이는 것.
- 같은 난수 인덱스가 생성되도록 np.random.permutation()을 호출하기 전에 난수 발생기의 초깃값을 지정하는 것.(np.random.seed(42))
train_test_split
- 난수 초깃값을 지정할 수 있는 random_state 매개변수가 있다.
- 행의 개수가 같은 여러 개의 데이터셋을 넘겨서 동일한 인덱스를 기반으로 나눌 수 있다. (DF이 레이블에 따라 여러 개로 나뉘어 있을 때 유용)
1
2
3
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
계층적 샘플링
- 전체 인구는 계층이라는 동질의 그룹으로 나뉘고, 테스트 세트가 전체 인구를 대표하도록 각 계층에서 올바를 수의 샘플을 추출.
❓ 나쁜 샘플을 얻을 확률 10.7%를 계산하는 방법
1
2
3
4
5
6
7
from scipy.stats import binom
sample_size = 1000
ratio_female = 0.511
proba_too_small = binom(sample_size, ratio_female).cdf(485 - 1)
proba_too_large = 1 - binom(sample_size, ratio_female).cdf(535)
print(proba_too_small + proba_too_large)
❓ 카테고리로 나누기
- 너무 많은 계층으로 나누면 안됨.
- 각 계층이 충분히 커야함.
1
housing["income_cat"] = pd.cut(housing["median_income"], bins=[0., 1.5, 3.0, 4.5, 6., np.inf], labels=[1, 2, 3, 4, 5])
❓ 분할기
- split()
- 훈련과 테스트 데이터 자체가 아니라 인덱스를 반환.
1
2
strat_train_set, strat_test_set = train_test_split(
housing, test_size=0.2, stratify=housing["income_cat"], random_state=42)
2.4 데이터 이해를 위한 탐색과 시각화
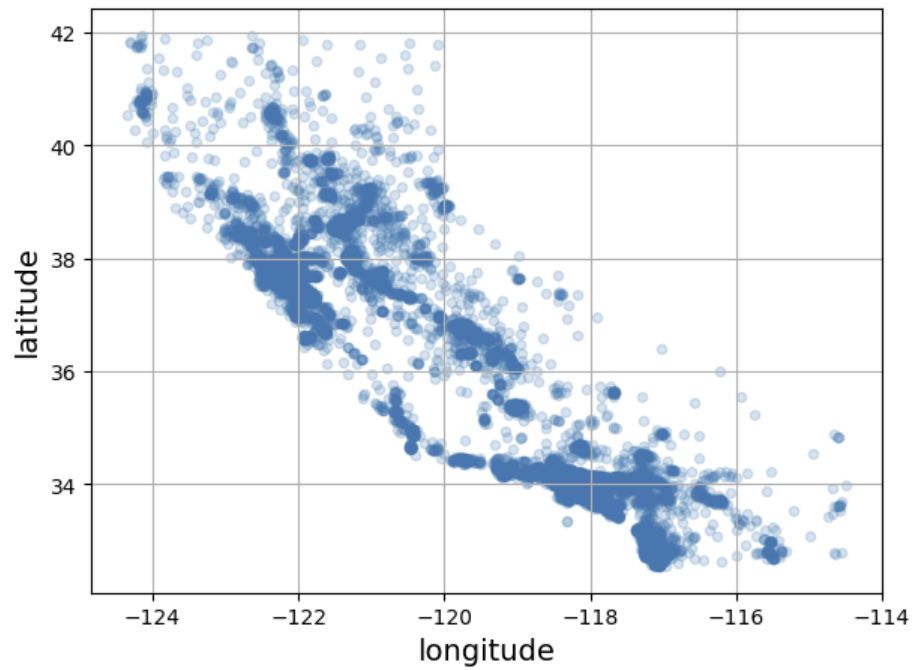
2.4.1 지리적 데이터 시각화하기
1
2
3
housing.plot(kind="scatter", x="longitude", y="latitude", grid=True, alpha=0.2)
save_fig("better_visualization_plot") # extra code
plt.show()
1
2
3
4
5
6
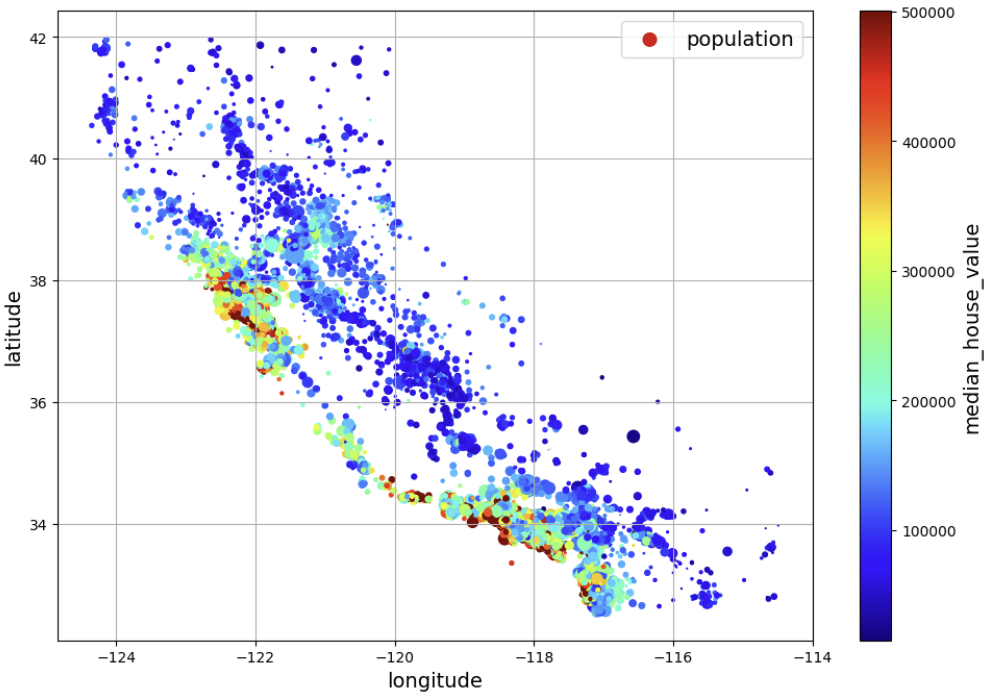
housing.plot(kind="scatter", x="longitude", y="latitude", grid=True,
s=housing["population"] / 100, label="population",
c="median_house_value", cmap="jet", colorbar=True,
legend=True, figsize=(10, 7))
save_fig("housing_prices_scatterplot") # extra code
plt.show()
2.4.2 상관관계 조사하기
- corr(): 표준 상관계수 (피어슨의 r)
1
corr_matrix = housing.corr(numeric_only=True)
1
2
3
4
5
6
7
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
save_fig("scatter_matrix_plot") # 추가 코드
plt.show()
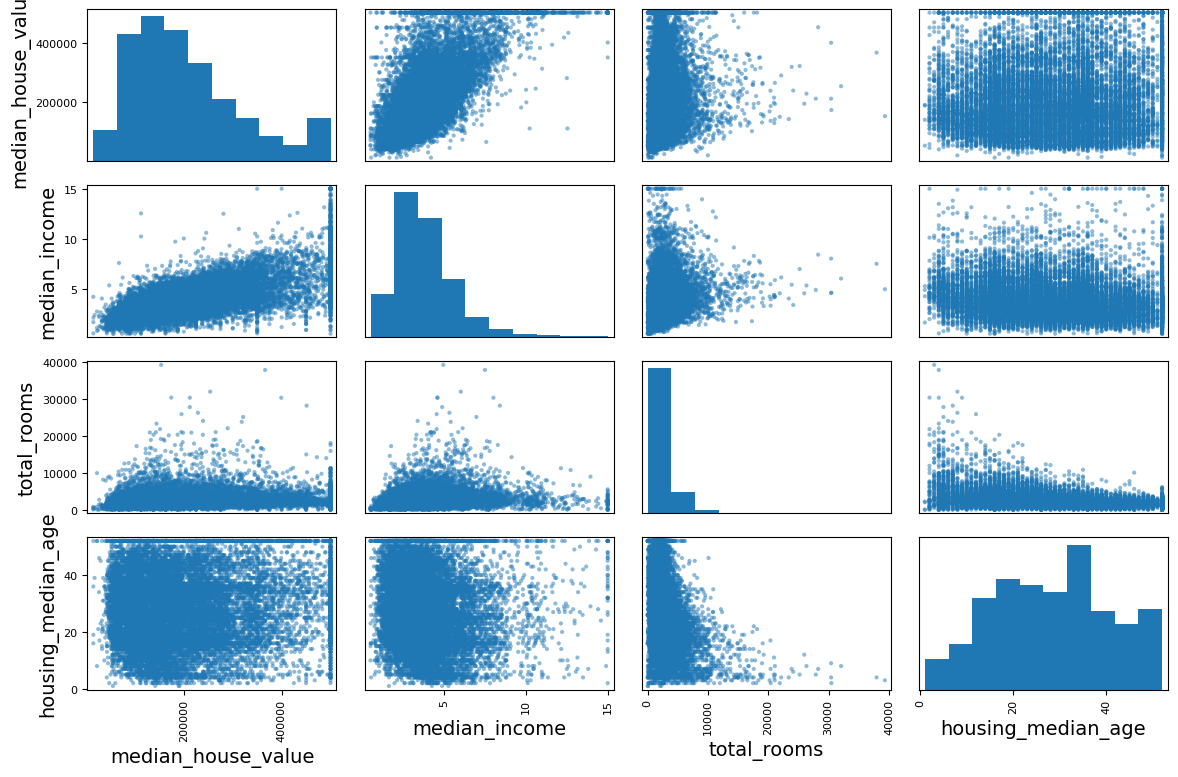
❗ 오른쪽으로 꼬리가 긴 데이터는 로그 함수나 제곱근을 이용해 변형해도 됨.
2.4.3 특성 조합으로 실험하기
1
2
3
housing["rooms_per_house"] = housing["total_rooms"] / housing["households"]
housing["bedrooms_ratio"] = housing["total_bedrooms"] / housing["total_rooms"]
housing["people_per_house"] = housing["population"] / housing["households"]
- 필요해 보이는 특성 만들기!
2.5 머신러닝 알고리즘을 위한 데이터 준비
수동으로 하는 것 대신, 함수를 만들어 자동화해야 하는 이유
- 어떤 데이터셋에 대해서도 데이터 변환을 손쉽게 반복할 수 있습니다.
- 향후 프로젝트에 재사용 가능한 변환 라이브러리를 점진적으로 구축할 수 있습니다.
- 실제 시스템에서 알고리즘에 새 데이터를 주입하기 전에 이 함수를 사용해 변환할 수 있습니다.
- 여러 가지 데이터 변환을 쉽게 시도해볼 수 있고 어떤 조합이 좋은지 확인하는데 편리합니다.
1
2
3
housing = strat_train_set.drop("median_house_value", axis=1)
# .drop(): 기본적으로 데이터 복사본을 만들어 반환하며 strat_train_set에는 영향을 주지 않습니다.
housing_labels = strat_train_set["median_house_value"].copy()
2.5.1 데이터 정제
- 해당 구역 제거 (dropna)
- 전체 특성 삭제 (drop)
- 누락된 값 대체 (fillna)
1
2
3
4
5
6
housing.dropna(subset=["total_bedrooms"], inplace=True) # 옵션 1
housing.drop("total_bedrooms", axis=1) # 옵션 2
median = housing["total_bedrooms"].median() # 옵션 3
housing["total_bedrooms"].fillna(median, inplace=True)
SimpleImputer 클래스 사용
1
2
3
4
5
6
7
8
9
10
11
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
housing_num = housing.select_dtypes(include=[np.number])
# 숫자 타입인 열만 추출
imputer.fit(housing_num)
# 각 특성의 중간값을 계산해서 그 결과를 객체의 statistics_ 속성에 저장.
X = imputer.transform(housing_num)
⭐ 누락된 값 대체 위한 더 강력한 클래스들!
- most_frequent: 최빈값
- constant: 상수
- KNNImputer: 누락된 값을 이 특성에 대한 k-최근접 이웃의 평균으로 대체.
- IterativeImputer: 특성마다 회귀 모델을 훈련하여 다른 모든 특성을 기반으로 누락된 값 예측.
⭐ 사이킷런의 설계 철학
- 일관성
- 추정기(estimator)
- 데이터셋을 기반으로 일련의 모델 파라미터들을 추정하는 객체.(imputer) 추정 자체는 fit() 메서드에 의해 수행되고 하나의 매개변수로 하나의 데이터셋만 전달. 추정 과정에서 필요한 다른 매개변수들은 모두 하이퍼파라미터로 간주되고, 인스턴스 변수로 저장.
- 변환기(transformer)
- 데이터셋을 변환하는 추정기. 변환은 imputer의 경우와 같이 학습된 모델 파라미터에 의해 결정. 모든 변환기는 fit_transformer를 가짐.
- 판다스 데이터프레임이 입력되더라도 넘파이 배열을 출력.
- 예측기(predictor)
- 새로운 데이터셋을 받아 이에 상응하는 예측값을 반환. 또한 테스트 세트를 사용해 예측의 품질을 측정하는 score() 메서드를 가짐.
- 추정기(estimator)
- 검사 가능
- 클래스 남용 방지
- 조합성
- 합리적인 기본값
2.5.2 텍스트와 범주형 특성 다루기
OrdinalEncoder 클래스
1
2
3
4
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
❗문제!
- 거리에 의미가 부여됨.(bad, good과 같은 경우에는 상관이 없는데 위와 같은 경우는 상관 O)
원핫 인코딩
- 한 특성만 1이고 나머지는 0.
- 더미 특성: 새로운 특성
1
2
3
4
5
6
7
8
9
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
# OneHotEncoder(sparse=False)로 하면, 넘파이 배열 반환.
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
# OneHotEncoder()은 희소 행렬을 반환.
housing_cat_1hot.toarray()
# toarray()를 이용해 밀집 배열로 반환 가능.
⭐ get_dummies()
- get_dummies()는 OneHotEncoder와 다르게 카테고리로 훈련되어있지 않습니다.
- 알 수 없는 카테고리를 감지하면 예외를 발생시킵니다. (handle_unkown 매개변수를 ‘ignore’로 지정하면 알 수 없는 카테고리를 그냥 0으로 나타낼 수 있습니다.)
❓ 카테고리 특성이 너무 많다면?
- 이 특성과 관련된 숫자형 특성으로 바꾸기! (ex. 국가 코드는 인구와 1인당 GDP로 바꿀 수 있다.)
- category_encoders 패키지가 제공하는 인코더 중 하나 이용 가능.
- 임베딩이라 부르는 학습 가능한 저차원 벡터로 바꿀 수O (표현 학습의 한 예시)
2.5.3 특성 스케일과 변환
❗훈련 세트 이외의 어떤 것에도 fit()이나 fit_transform() 메서드를 사용해서는 안된다. 훈련하고 나면 이를 사용해 다양한 data set에 transform() 메서드를 적용할 수 있다.
❗훈련 세트 값은 항상 특정 범위로 스케일링되지만 새로운 데이터에 이상치가 있다면, 이 범위 밖으로 스케일링 된다. 이를 원치 않으면 MinMaxScaler의 clip 매개변수를 True로 지정!
입력 특성 변환
- min-max 스케일링 (정규화)
1
2
3
4
5
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler(feature_range=(-1, 1))
# feature_range로 범위 설정
housing_num_min_max_scaled = min_max_scaler.fit_transform(housing_num)
- 표준화
- 이상치에 영향 덜 받음.
1
2
3
4
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
housing_num_std_scaled = std_scaler.fit_transform(housing_num)
➕ 멱법칙 분포처럼 특성 분포의 꼬리가 아주 길고 두껍다면?
- 특성을 로그값으로 바꾸기
- 버킷타이징
- 멀티모달 분포(최댓값이 2개 이상 나타나는 분포)
- 이때는 버킷 id를 수치가 아닌, 카테고리로 다룸.(버킷 id를 OneHotEncoder를 이용해 인코딩 해야함.)
- 멀티모달 분포를 변환하는 또다른 방안: 중간 주택 연도와 특정 모드 사이의 유사도를 나타내는 특성을 추가하는 것! (by 방사 기저 함수 - 입력 값이 고정 포인트에서 멀어질수록 출력값이 지수적으로 감소하는 가우스 RBF)
1 2 3 4
from sklearn.metrics.pairwise import rbf_kernel age_simil_35 = rbf_kernel(housing[["housing_median_age"]], [[35]], gamma=0.1) # 감마:기준 값에서 멀어짐에 따라 유사도 값이 얼마나 빠르게 감소하나?
- 특성값의 여러 범주에 대해 다양한 규칙 쉽게 학습!
- 멀티모달 분포(최댓값이 2개 이상 나타나는 분포)
타깃값 변환
1
2
3
4
5
6
7
8
9
10
11
12
13
from sklearn.linear_model import LinearRegression
target_scaler = StandardScaler()
scaled_labels = target_scaler.fit_transform(housing_labels.to_frame())
# standardScaler는 2D 입력을 기대함.
model = LinearRegression()
model.fit(housing[["median_income"]], scaled_labels)
some_new_data = housing[["median_income"]].iloc[:5] # 새로운 데이터라고 가정합니다
scaled_predictions = model.predict(some_new_data)
predictions = target_scaler.inverse_transform(scaled_predictions)
# 원래 스케일로 되돌림.
더 간단하게!! TransformedTargetRegressor 이용!
1
2
3
4
5
6
7
from sklearn.compose import TransformedTargetRegressor
model = TransformedTargetRegressor(LinearRegression(),
transformer=StandardScaler())
model.fit(housing[["median_income"]], housing_labels)
predictions = model.predict(some_new_data)
# 이때 predict() 메서드와 inverse_transform() 메서드를 사용하여 예측 생성.
2.5.4 사용자 정의 변환기
- 어떤 훈련도 필요하지 않는 변환.
1
2
3
4
5
from sklearn.preprocessing import FunctionTransformer
log_transformer = FunctionTransformer(np.log, inverse_func=np.exp)
# inverse_func 매개변수는 선택사항. (ex. TransformedTargetRegressor에 이 변환기를 이용할 예정이면 inverse_func 매개변수에 역변수 함수를 지정할 수 있음)
log_pop = log_transformer.transform(housing[["population"]])
- 추가적인 인수로 하이퍼파라미터를 받을 수 있음.
1
2
3
rbf_transformer = FunctionTransformer(rbf_kernel,
kw_args=dict(Y=[[35.]], gamma=0.1))
age_simil_35 = rbf_transformer.transform(housing[["housing_median_age"]])
❗ rbf 커널은 고정 포인트에서 일정 거리만큼 떨어진 값이 항상 2개 이기에, 역함수 없음.
❗rbf 커널은 특성을 개별적으로 처리X 두 개의 특성을 가진 배열을 전달하면 유사도를 측정하기 위해 2D 거리(유클리드 거리)를 계산함.
1
2
3
4
sf_coords = 37.7749, -122.41
sf_transformer = FunctionTransformer(rbf_kernel,
kw_args=dict(Y=[sf_coords], gamma=0.1))
sf_simil = sf_transformer.transform(housing[["latitude", "longitude"]])
- 특성을 합칠 때도 유용하다. (FunctionTransformer)
1
2
ratio_transformer = FunctionTransformer(lambda X: X[:, [0]] / X[:, [1]])
ratio_transformer.transform(np.array([[1., 2.], [3., 4.]]))
- 훈련 가능한 변환기가 필요하다면? (데이터 분포가 다르면 곤란하기 때문)
- 사이킷런은 덕 타이핑(상속이나 인터페이스 구현이 아니라 객체의 속성이나 메서드가 객체의 유형을 결정하는 방식)에 의존하기 때문에 이 클래스가 특정 클래스를 상속할 필요X
- fit_transform() 메서드는 TransformerMixin을 상속하면 자동으로 생성된다.
- BaseEstimator를 상속하면 하이퍼파라미터 튜닝에 필요한 두 메서드 (get_params()와 set_params())를 추가로 얻게됨.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# StandardScaler와 비슷하게 작동하는 사용자 정의 변환기
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils.validation import check_array, check_is_fitted
class StandardScalerClone(BaseEstimator, TransformerMixin):
def __init__(self, with_mean=True): # *args나 **kwargs를 사용하지 않습니다!
self.with_mean = with_mean
def fit(self, X, y=None): # 사용하지 않더라도 y를 넣어 주어야 합니다
X = check_array(X) # X가 부동소수점(실수(소수점이 있는 숫자)를 저장하는 배열) 배열인지 확인합니다
self.mean_ = X.mean(axis=0)
self.scale_ = X.std(axis=0)
self.n_features_in_ = X.shape[1] # 모든 추정기는 fit()에서 이를 저장합니다.
return self # 항상 self를 반환합니다!
def transform(self, X):
check_is_fitted(self) # (훈련으로) 학습된 속성이 있는지 확인합니다
X = check_array(X)
assert self.n_features_in_ == X.shape[1]
if self.with_mean:
X = X - self.mean_
return X / self.scale_
💡주의 사항
- Sklearn.utils.validation 패키지에는 입력을 검증하기 위해 사용할 수 있는 함수가 여러 개 있다.
- 사이킷런 파이프라인은 X와 y 두 개의 매개변수를 가진 메서드가 필요하다. y를 사용하지 않지만, y=None이 필요!
- 모든 추정기는 fit()에 n_features_in_을 설정하고 transform()이나 predict()를 수행할때 특성 개수가 같은지 확인!
- fit() 메서드는 self 반환!
- 모든 추정기는 df이 전달될 때 fit() 안에서 feature_names_in을 설정해야한다. 또한 모든 변환기는 get_feature_names_out() 메서드와 역변환을 위한 inverse_transform() 메서드를 제공해야 한다.
- 하나의 사용자 변환기는 구현 안에서 다른 추정기 이용 가능.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# fit() 안에서 훈련 데이터에 있는 핵심 클러스터를 식별 하기 위해 KMeans 클래스를 사용
# transform() 안에서 rbf_kernel()을 이용해 각 샘플이 클러스터 중심과 얼마나 유사한지 측정
from sklearn.cluster import KMeans
class ClusterSimilarity(BaseEstimator, TransformerMixin):
def __init__(self, n_clusters=10, gamma=1.0, random_state=None):
self.n_clusters = n_clusters
self.gamma = gamma
self.random_state = random_state
def fit(self, X, y=None, sample_weight=None):
# 사이킷런 1.2버전에서 최상의 결과를 찾기 위해 반복하는 횟수를 지정하는 `n_init` 매개변수 값에 `'auto'`가 추가되었습니다.
# `n_init='auto'`로 지정하면 초기화 방법을 지정하는 `init='random'`일 때 10, `init='k-means++'`일 때 1이 됩니다.
# 사이킷런 1.4버전에서 `n_init`의 기본값이 10에서 `'auto'`로 바뀝니다. 경고를 피하기 위해 `n_init=10`으로 지정합니다.
self.kmeans_ = KMeans(self.n_clusters, n_init=10, random_state=self.random_state)
self.kmeans_.fit(X, sample_weight=sample_weight)
return self # 항상 self를 반환합니다!
def transform(self, X):
return rbf_kernel(X, self.kmeans_.cluster_centers_, gamma=self.gamma)
def get_feature_names_out(self, names=None):
return [f"클러스터 {i} 유사도" for i in range(self.n_clusters)]
2.5.5 변환 파이프라인
- Pipeline 클래스 제공
- (이름/추정기) 쌍의 리스트를 받음.
- 추정기는 마지막을 제외하고 모두 변환기여야함.
- 마지막 추정기는 변환기, 예측기부터 다른 타입의 추정기까지 모두 가능!!
- 파이프라인은 인덱싱을 지원함. (ex.pipline[1], num_pipeline.named_steps[“simpleimputer”])
- 파라미터 조정 가능 (ex.num_pipeline.set_params(simpleimputer__strategy=”median”))
1
2
3
4
5
6
7
8
9
10
11
# 수치 특성에서 누락된 값을 대체하고 스케일을 조정
from sklearn.pipeline import Pipeline
num_pipeline = Pipeline([
("impute", SimpleImputer(strategy="median")),
("standardize", StandardScaler()),
])
# 이름 짓는게 귀찮다면?
# from sklearn.pipeline import make_pipeline
# num_pipeline = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())
⭐주피터 노트북에서 import sklearn과 sklearn.set_config(display=’diagram )을 실행하면 다이어그램으로 표현!
1
2
3
4
5
from sklearn import set_config
set_config(display='diagram')
num_pipeline
- ColumnTransformer 이용
- 하나의 변환기로 각 열마다 적절한 변환 적용 가능.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# num_pipeline - 수치형 / cat_pipeline - 범주형
from sklearn.compose import ColumnTransformer
num_attribs = ["longitude", "latitude", "housing_median_age", "total_rooms",
"total_bedrooms", "population", "households", "median_income"]
cat_attribs = ["ocean_proximity"]
cat_pipeline = make_pipeline(
SimpleImputer(strategy="most_frequent"),
OneHotEncoder(handle_unknown="ignore"))
preprocessing = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", cat_pipeline, cat_attribs),
])
attributes를 이렇게 지정하는것이 귀찮다면?
=> make_column_selector 클래스 이용!!
1
2
3
4
5
6
7
from sklearn.compose import make_column_selector, make_column_transformer
preprocessing = make_column_transformer(
# 변환기에 이름 짓는것이 귀찮을 때 이용!
(num_pipeline, make_column_selector(dtype_include=np.number)),
(cat_pipeline, make_column_selector(dtype_include=object)),
)
⭐희소 행렬과 밀집 행렬이 섞여 있을 때 ColumnTransformer는 최종 행렬의 밀집 정도를 추정. 밀집도가 임계값(기본적으로 sparse_threshold=0.3 이다)보다 낮으면 희소 행렬을 반환합니다.
최종 파이프라인 만들기!!
💡조건
- 누락된 값 -> 중간값으로 대체!
- 범주형 특성을 원-핫 인코딩!
- 비율 특성을 계산하여 추가.
- 클러스터 유사도 측정.
- 대부분의 모델은 균등 분포나 가우스 분포에 가까운 특성을 선호하기 때문에 꼬리가 두꺼운 분포를 띠는 특성을 로그값으로 변경!
- 표준화.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def column_ratio(X):
return X[:, [0]] / X[:, [1]]
def ratio_name(function_transformer, feature_names_in):
return ["ratio"] # get_feature_names_out에 사용
def ratio_pipeline():
return make_pipeline(
SimpleImputer(strategy="median"),
FunctionTransformer(column_ratio, feature_names_out=ratio_name),
StandardScaler())
log_pipeline = make_pipeline(
SimpleImputer(strategy="median"),
FunctionTransformer(np.log, feature_names_out="one-to-one"),
StandardScaler())
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1., random_state=42)
default_num_pipeline = make_pipeline(SimpleImputer(strategy="median"),
StandardScaler())
preprocessing = ColumnTransformer([
("bedrooms", ratio_pipeline(), ["total_bedrooms", "total_rooms"]),
("rooms_per_house", ratio_pipeline(), ["total_rooms", "households"]),
("people_per_house", ratio_pipeline(), ["population", "households"]),
("log", log_pipeline, ["total_bedrooms", "total_rooms", "population",
"households", "median_income"]),
("geo", cluster_simil, ["latitude", "longitude"]),
("cat", cat_pipeline, make_column_selector(dtype_include=object)),
],
remainder=default_num_pipeline) # 남은 특성: housing_median_age
housing_prepared = preprocessing.fit_transform(housing)
housing_prepared.shape
preprocessing.get_feature_names_out()
2.6 모델 선택과 훈련
완료한 것!
- 훈련 세트와 테스트 세트 나누기
- 전처리 파이프라인 작성
2.6.1 훈련 세트에서 훈련하고 평가하기
훈련하기1 (선형회귀 모델)
1
2
3
4
5
6
7
from sklearn.linear_model import LinearRegression
lin_reg = make_pipeline(preprocessing, LinearRegression())
lin_reg.fit(housing, housing_labels)
housing_predictions = lin_reg.predict(housing)
housing_predictions[:5].round(-2) # -2 = 십의 자리에서 반올림
평가하기(RMSE)
- mean_squared_error() 함수 사용
1
2
3
4
5
6
7
from sklearn.metrics import mean_squared_error
lin_rmse = mean_squared_error(housing_labels, housing_predictions,
squared=False)
lin_rmse
# np.float64(65778.48225643061)
# 과소적합!!
훈련하기2 (결정 트리)
1
2
3
4
from sklearn.tree import DecisionTreeRegressor
tree_reg = make_pipeline(preprocessing, DecisionTreeRegressor(random_state=42))
tree_reg.fit(housing, housing_labels)
평가하기 (RMSE)
엥? 이상한데? 테스트 세트는 아직 이용하면 안되기 때문에, 훈련 세트의 일부분으로 훈련하고 다른 일부분으로 모델 검증!!
2.6.2 교차 검증으로 평가하기
- K-폴드 교차 검증 이용!
결정 트리
1
2
3
4
5
from sklearn.model_selection import cross_val_score
tree_rmses = -cross_val_score(tree_reg, housing, housing_labels,
scoring="neg_root_mean_squared_error", cv=10)
# 사이킷런의 교차 검증 기능은 scoring 매개변수에 효용 함수 기대! 그래서 RMSE의 음숫값인 neg_mean_squared_error 이용
1
2
3
pd.Series(tree_rmses).describe()
# 평균 RMSE: 66,868 / 표준 편차: 2,061
# 과대적합!
RandomForestRegressor
- 특성을 랜덤으로 선택해서 많은 결정 트리를 만들고 예측의 평균을 구하는 방식으로 작동.
- 서로 다른 모델들로 구성된 이런 모델을 앙상블이라고 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sklearn.ensemble import RandomForestRegressor
forest_reg = make_pipeline(preprocessing,
RandomForestRegressor(random_state=42))
forest_rmses = -cross_val_score(forest_reg, housing, housing_labels,
scoring="neg_root_mean_squared_error", cv=10)
pd.Series(forest_rmses).describe()
# mean 45712.814157
forest_reg.fit(housing, housing_labels)
housing_predictions = forest_reg.predict(housing)
forest_rmse = mean_squared_error(housing_labels, housing_predictions,
squared=False)
forest_rmse
# 16952
과대적합!!
=> 하이퍼파라미터 조정에 많은 시간을 들이기 전에, 다양한 머신러닝 모델(다양한 커널의 SVM, 신경망 등) 시도!
2.7 모델 미세 튜닝
➡️가능성 있는 모델들을 추렸다고 가정!
2.7.1 그리드 서치
- 사이킷런의 GridSearchCV 이용.
- 파이프라인이나 ColumnTransformer가 추정기를 겹겹이 감싸고 있더라도 추정기의 모든 하이퍼파라미터를 지정할 수 있다.
- 이중 밑줄 문자를 기준으로 나누고 차례로 찾음!
- GridSearchCV가 기본값인 refit=True로 초기화되었다면, 교차 검증으로 최적의 추정기를 찾은 다음 전체 훈련 세트로 다시 훈련시킴.
- 파이프라인이나 ColumnTransformer가 추정기를 겹겹이 감싸고 있더라도 추정기의 모든 하이퍼파라미터를 지정할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sklearn.model_selection import GridSearchCV
full_pipeline = Pipeline([
("preprocessing", preprocessing),
("random_forest", RandomForestRegressor(random_state=42)),
])
param_grid = [
{'preprocessing__geo__n_clusters': [5, 8, 10],
'random_forest__max_features': [4, 6, 8]},
{'preprocessing__geo__n_clusters': [10, 15],
'random_forest__max_features': [6, 8, 10]},
]
grid_search = GridSearchCV(full_pipeline, param_grid, cv=3,
scoring='neg_root_mean_squared_error')
grid_search.fit(housing, housing_labels)
1
2
grid_search.best_params_
# 최상의 조합 확인
⭐파이프라인 변환기를 훈련하는데 계산 비용이 많이 든다면 파이프라인의 memory 매개변수에 캐싱 디렉터리 경로를 지정할 수 있음.
2.7.2 랜덤 서치
- RandomizedSearchCV
- 하이퍼파라미터 탐색 공간이 커지면 유용.
- 가능한 모든 조합 시도X 각 반복마다 하이퍼파라미터에 임의의 수 대입.
- 하이퍼파라미터마다 가능한 값의 리스트나 확률 분포를 제공해야 함.
1
2
3
4
5
6
7
8
9
10
11
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {'preprocessing__geo__n_clusters': randint(low=3, high=50),
'random_forest__max_features': randint(low=2, high=20)}
rnd_search = RandomizedSearchCV(
full_pipeline, param_distributions=param_distribs, n_iter=10, cv=3,
scoring='neg_root_mean_squared_error', random_state=42)
rnd_search.fit(housing, housing_labels)
➕HalvingRandomSearchCV와 HalvingGridSearchCV
- 첫 번째 반복에서 많은 하이퍼파라미터 조합이 그리드 서치나 랜덤 서치를 이용해 생성.
- 이 후보들을 사용해 훈련하고 교차 검증 사용해 평가. 하지만, 첫번째 반복의 속도를 높이기 위해 제한된 자원(일부 훈련 세트 이용)으로 훈련
- 모든 후보 평가 후, 최상의 후보만 다음 단계로 넘어가 더 많은 자원을 이용.
- 몇번의 반복후, 최종 후보들이 전체 자원 사용해 평가.
➕보너스 섹션: 하이퍼파라미터를 위한 샘플링 분포 선택 방법
scipy.stats.randint(a, b+1): a~b 사이의 이산적인 값을 가진 하이퍼파라미터. 이 범위의 모든 값은 동일한 확률 가집니다.scipy.stats.uniform(a, b): 매우 비슷하지만 연속적인 파라미터에 사용합니다.scipy.stats.geom(1 / scale): 이산적인 값의 경우 주어진 스케일 안에서 샘플링하고 싶을 때 사용합니다. 예를 들어 scale=1000인 경우 대부분의 샘플은 이 범주 안에 있지만 모든 샘플 중 10% 정도는 100보다 작고, 10% 정도는 2300보다 큽니다.scipy.stats.expon(scale):geom의 연속적인 버전입니다.scale을 가장 많이 등장할 값으로 지정합니다.scipy.stats.loguniform(a, b): 하이퍼파라미터 값의 스케일을 어떻게 지정할지 모를 때 사용합니다. a=0.01, b=100으로 지정하면 0.01과 0.1 사이의 샘플링과 10과 100 사이의 샘플링 비율이 동일합니다.
2.7.3 앙상블 기법
- 최상의 모델을 연결해 보는 것!
- ex) K-최근접 이웃 모델을 훈련하고 미세 튜닝한 다음 이 모델의 예측과 랜덤 포레스트의 예측을 평균하여 예측으로 삼는 것.
2.7.4 최상의 모델과 오차 분석
- 최상의 모델을 분석하면, 문제에 대한 좋은 인사이트를 얻는 경우 있음.
- 각 특성의 상대적 중요도를 알 수O
1
2
3
final_model = rnd_search.best_estimator_ # 전처리 포함됨
feature_importances = final_model["random_forest"].feature_importances_
feature_importances.round(2)
⭐ sklearn.feature_selection.SelectFromModel 변환기
- 자동으로 가장 덜 유용한 특성을 제거할 수 있음.
- 이 변환기를 훈련하면, 한 모델을 훈련하고, feature_importances_ 속성을 확인하여 가장 유용한 특성을 선택. 그다음 transform() 메서드를 호출할 때 다른 특성을 삭제.
2.7.5 테스트 세트로 시스템 평가하기
1
2
3
4
5
6
7
8
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
final_predictions = final_model.predict(X_test)
final_rmse = mean_squared_error(y_test, final_predictions, squared=False)
print(final_rmse)
# 42537.741264526725
이 추정값이 얼마나 정확한가?
=> 신뢰구간 이용!
1
2
3
4
5
6
7
from scipy import stats
confidence = 0.95
squared_errors = (final_predictions - y_test) ** 2
np.sqrt(stats.t.interval(confidence, len(squared_errors) - 1,
loc=squared_errors.mean(),
scale=stats.sem(squared_errors)))

2.8 론칭, 모니터링, 시스템 유지 보수
모델 저장
- joblib 라이브러리 이용
1
2
3
import joblib
joblib.dump(final_model, "my_california_housing_model.pkl")
❗ 원하는 모델로 쉽게 돌아올 수 있도록 실험한 모든 모델을 저장하는 것이 좋다. 검증 점수와 검증 세트에 대한 실제 예측도 저장 가능.
저장된 모델 로드
- 모델이 이용하는 모든 사용자 정의 클래스와 함수를 먼저 임포트 해야함.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import joblib
# 추가 코드 – 책에는 간결함을 위해 제외함
from sklearn.cluster import KMeans
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.metrics.pairwise import rbf_kernel
def column_ratio(X):
return X[:, [0]] / X[:, [1]]
#class ClusterSimilarity(BaseEstimator, TransformerMixin):
# [...]
final_model_reloaded = joblib.load("my_california_housing_model.pkl")
new_data = housing.iloc[:5] # 새로운 구역이라 가정
predictions = final_model_reloaded.predict(new_data)
모델의 배포
- 웹 사이트 안에서 이용 가능
- 웹 애플리케이션이 REST API를 통해 질의할 수 있는 전용 웹 서비스로 모델을 감쌀 수 있음.
- 모델을 구글 버텍스 AI와 같은 클라우드에 배포하는 것.
- joblib을 이용해 모델 저장 -> 구글 클라우드 스토리지에 업로드 -> 구글 버텍스 AI로 이동하여 새로운 모델 버전을 만들고 GCS 파일을 지정.
- 로드 밸런싱과 자동 확장을 처리하는 웹 서비스 만들어짐!
모델 모니터링
- 지속적 모니터링 필요.
- 후속 시스템의 지표로 모델 성능 추정 가능.
- 사람의 분석이 필요할 수 있음.
➡️ 너무 일이 많아 ㅜㅜ 따라서! 가능한 많은 것을 자동화 해야함!
자동화
- 정기적으로 새로운 데이터를 수집하고 레이블을 단다.
- 모델을 훈련하고, 미세 튜닝하는 스크립트 작성.
- 업데이트된 테스트 세트에서 새로운 모델과 이전 모델을 평가하는 스크립트를 하나 더 작성!
만든 모든 모델 백업!!
- 새로운 모델이 작동하지 않을시, 이전 모델로 빠르게 롤백하기 위해!
⭐MLOPS 필요!!
직접 해보세요!!
💡정리
단계: 데이터 준비 -> 모니터링 도구 구축 -> 사람의 평가 파이프라인 세팅 -> 주기적인 모델 학습 자동화