2.데이터 다루기
2.데이터 다루기
2-1 훈련 세트와 테스트 세트
강화 학습: 타깃이 아니라 알고리즘이 행동한 결과로 얻은 보상을 사용해 학습
비지도 학습: 타깃 없이 입력 데이터만 이용/ 데이터 파악에 유용
- 지도 학습
- 훈련하기 위한 데이터와 정답 필요
- 데이터(입력) + 정답(타깃) = 훈련 데이터
- 특성: 입력으로 사용된 것

훈련 세트와 테스트 세트
- 테스트 세트: 평가에 사용하는 데이터
- 훈련 세트: 훈련에 사용되는 데이터
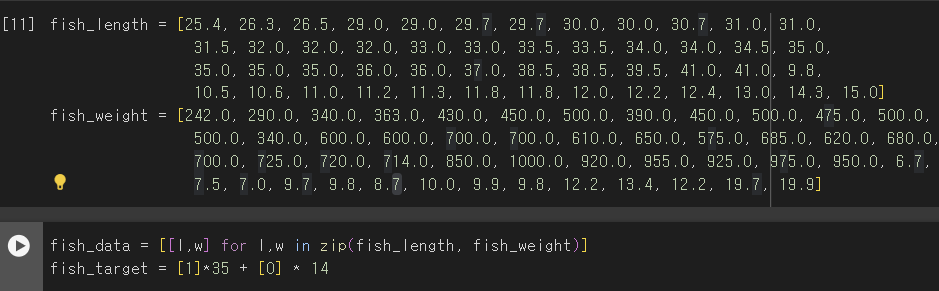
실습1
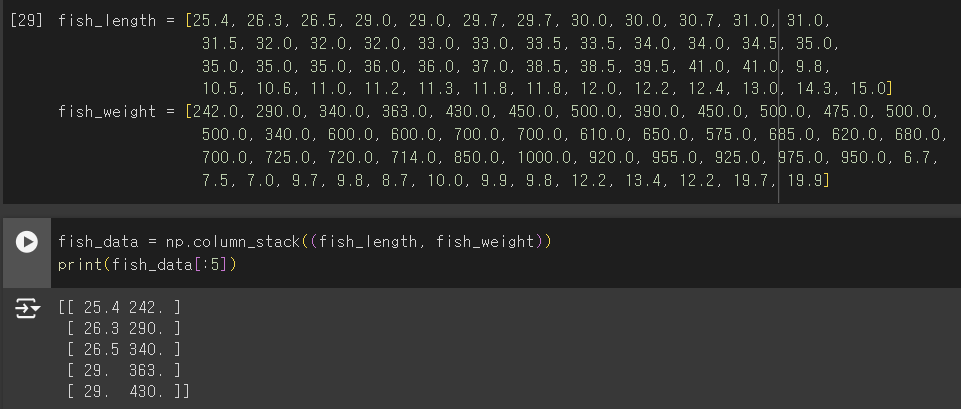
- 리스트 준비
- 샘플: 하나의 생선 데이터
- 모델 객체 만들기
- 샘플링 편향: 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않은 현상(훈련 세트에 도미만 있으니 정확도가 0!)
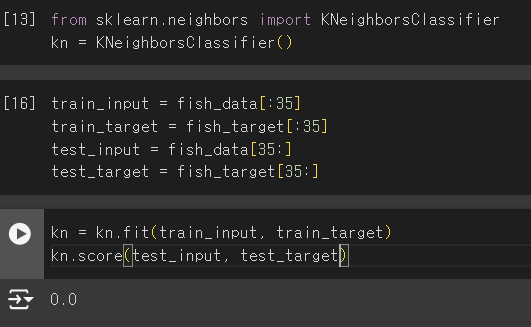
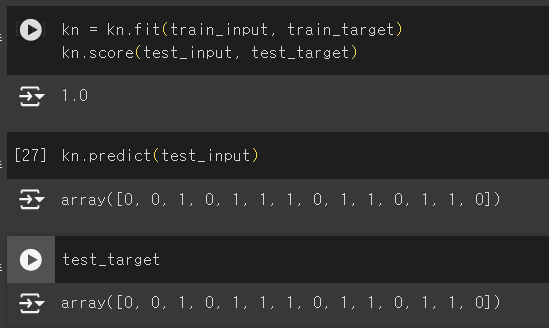
실습2(정확도 상승)
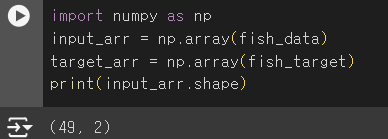
- 넘파이: 배열 라이브러리
- 2차원으로 만들기
- shape: 배열의 크기 알려줌.
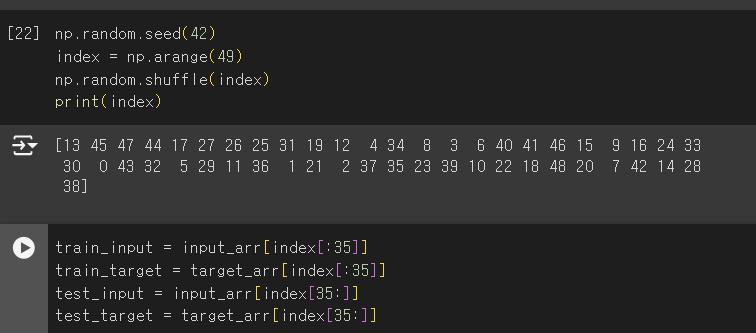
- 섞기
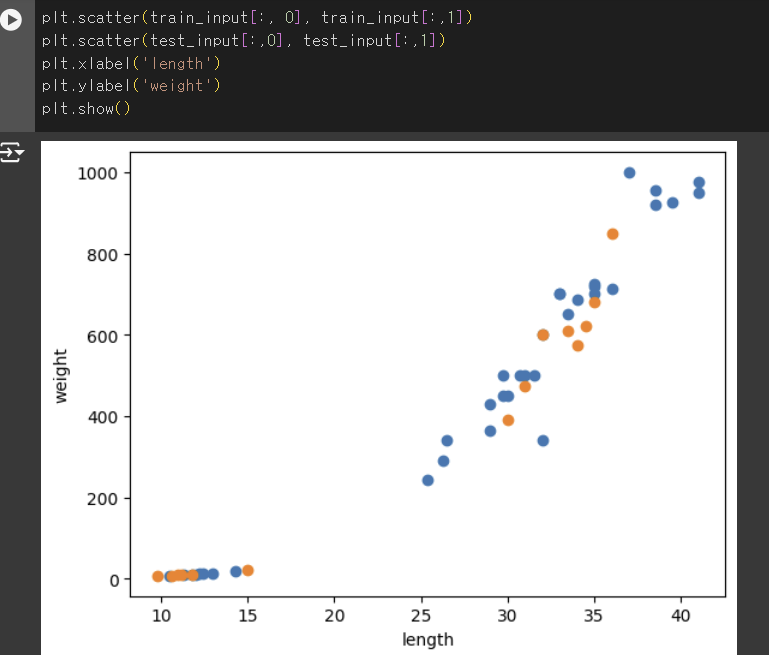
- 산점도 그리기
- 학습
넘파이
- seed(): 난수를 생성하기 위한 정수 초깃값. 초깃값이 같으면 동일한 난수를 뽑는다.
- arange(): 일정한 간격의 정수 또는 실수 배열을 만든다.
- 매개변수 1개: 종료 숫자
- 매개변수 2개: 시작 숫자, 종료 숫자
- 매개변수 3개: 마지막 매개변수가 간격
- shuffle(): 주어진 배열을 랜덤하게 섞는다.
2-2 데이터 전처리
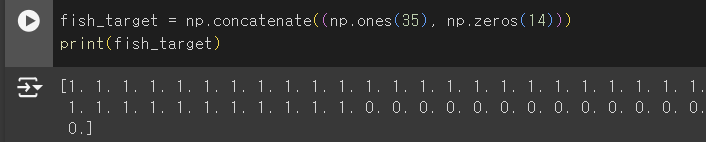
넘파이로 데이터 준비하기
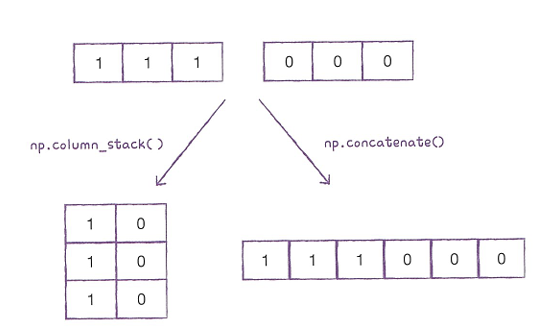
- column_stack(): 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결한다.
- np.column_stack() vs np.concatenate()
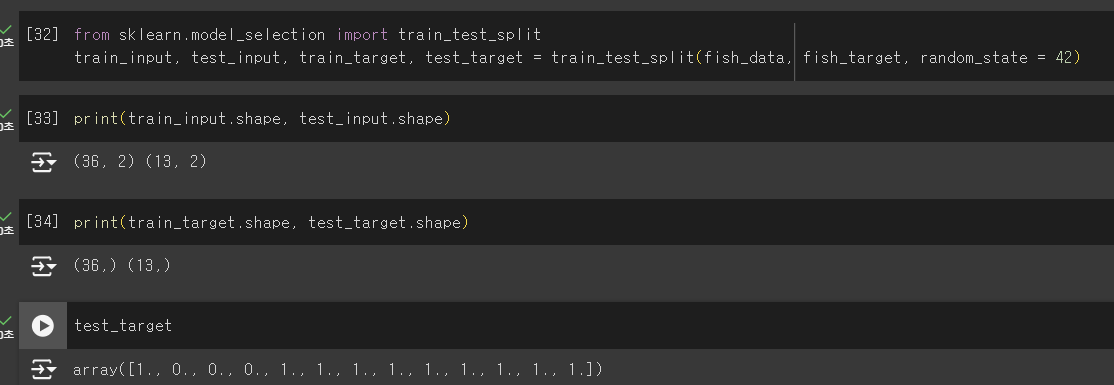
사이킷런으로 훈련 세트와 테스트 세트 나누기
train_test_split(): 전달되는 리스트나 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나누어 준다. 나누기 전에 섞어 준다.
stratify 매개변수: 클래스의 비율을 맞춰줌.

수상한 도미 한마리
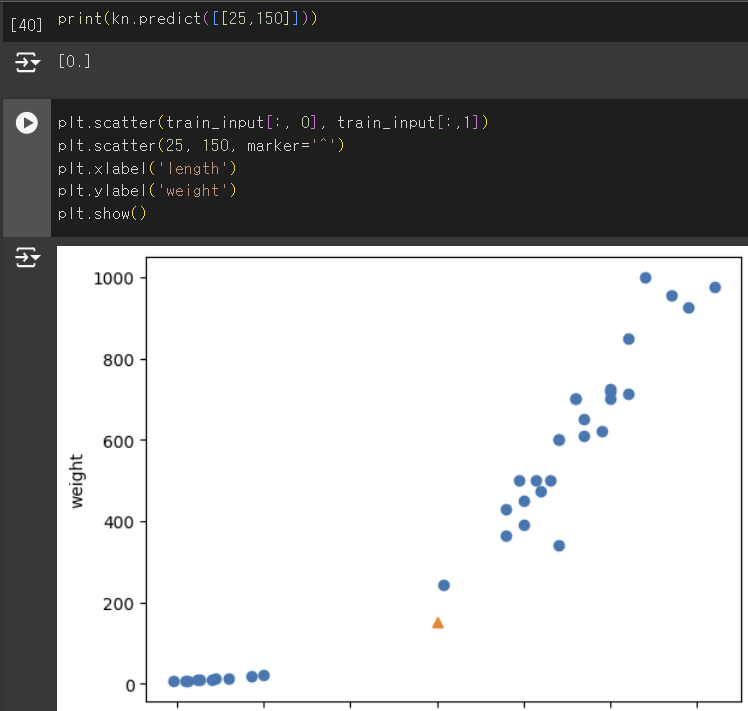
(25,150)은 도미에 가까운데 왜 빙어로 판단을 할까?
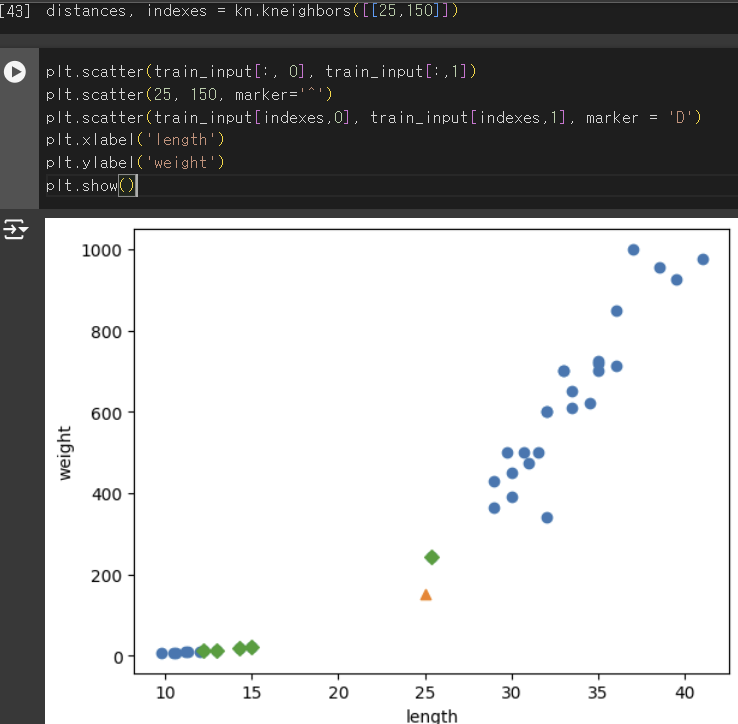

기준을 맞추자
- x축과 y축의 범위의 차이가 너무 커서 y값이 거리에 너무 영향을 많이 준다! -> x축의 범위를 동일하게 0 ~ 1000으로 맞추자.
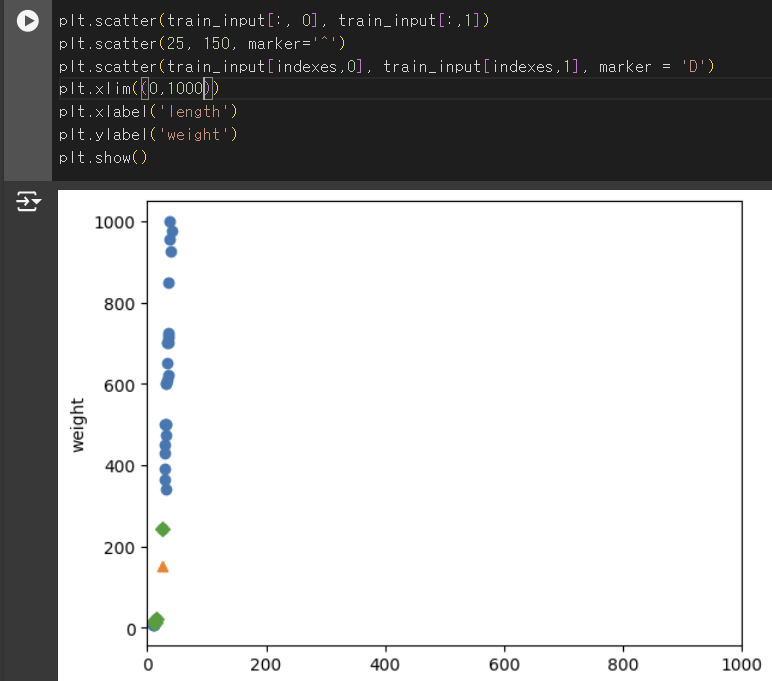
- 두 특성의 스케일이 너무 다르다!
따라서 데이터 전처리가 필요!!
- 표준점수 이용!
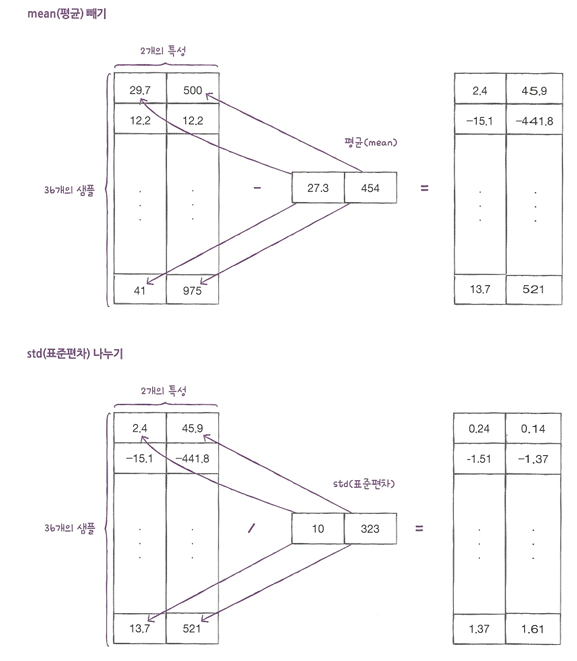
- 표준점수: 각 특성값이 0에서 표준편차의 몇 배만큼 떨어져 있는지를 나타냅니다. 이를 통해 실제 특성값의 크기와 상관없이 동일한 조건으로 비교할 수 있다.
- 평균을 빼고 표준편차를 나누어 주면 된다.
1 2
mean = np.mean(train_input, axis=0) std = np.std(train_input, axis=0)
- 이때 특성마다 값의 스케일이 다르므로 평균과 표준편차는 각 특성별로 계산해야 한다. 이를 위해 axis=0으로 지정한다. 이렇게 하면 행을 따라 각 열의 통계 값을 계산한다.
1
train_scaled = (train_input - mean) / std
- train_input의 모든 행에서 mean에 있는 두 평균값을 빼준다. 그다음 std에 있는 두 표준편차를 다시 모든 행에 적용한다 -> 브로드캐스팅
전처리 데이터로 모델 훈련하기
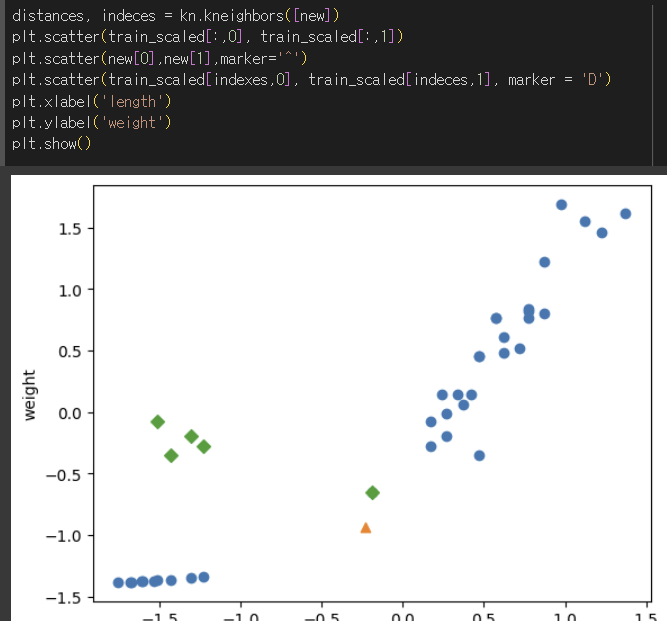
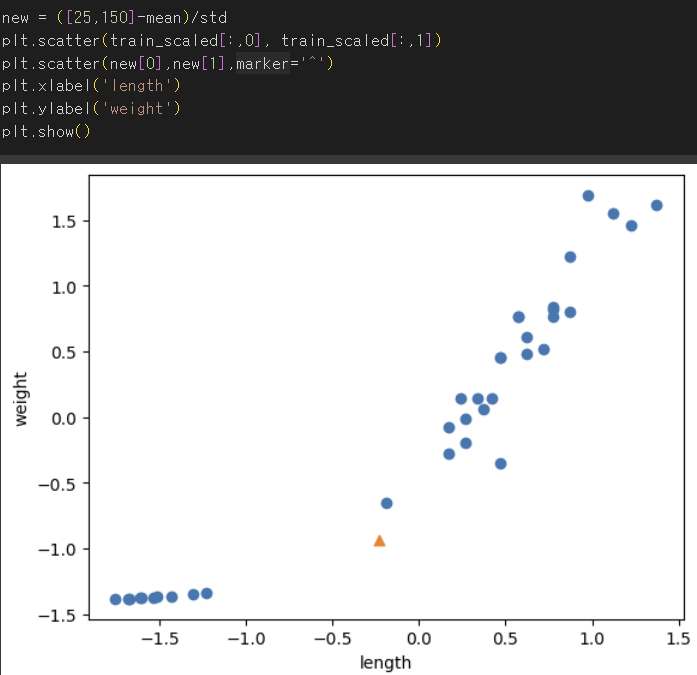 - 축의 범위가 -1.5 ~ 1.5로 바뀜.
- 축의 범위가 -1.5 ~ 1.5로 바뀜.
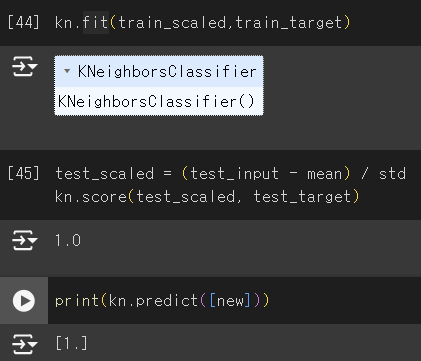
- 훈련 후 테스트 세트를 평가할 때는 테스트 세트의 기준으로 훈련 세트를 변환해야 같은 스케일로 산점도를 그릴 수 있음.
도미로 예측 성공!
정리
- 데이터 전처리 필요!
- 스케일이 다르면 모델 훈련이 잘 안될 수도 있음!
This post is licensed under CC BY 4.0 by the author.