[cv] deep residual learning for image recognition
[cv] deep residual learning for image recognition
기존 딥러닝의 문제점
선행 연구(해결법)
- normalized initialization
- intermediate normalization layers
=> 덕분에 SGD나 역전파로 수십개의 층 학습 가능.
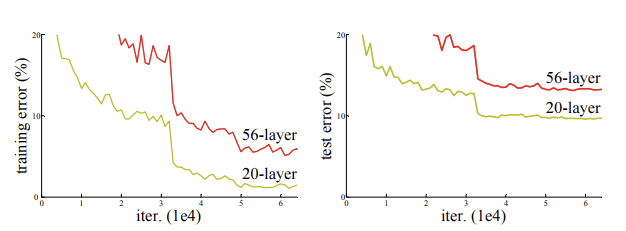
=> 더 깊은 네트워크들이 학습을 시작할 수 있게 되자, ‘성능 저하’ 문제가 드러남.
Resnet 아이디어
- 잔차 함수를 학습하는 것이 직접 H(x)를 학습하는 것보다 최적화가 훨씬 쉽다고 가정.
- 이건 “출력을 입력과 똑같이 만들어라”보다는 훨씬 쉬운 문제. 왜냐면 모델이 ‘아무것도 안 하기’를 배우면 되기 때문.
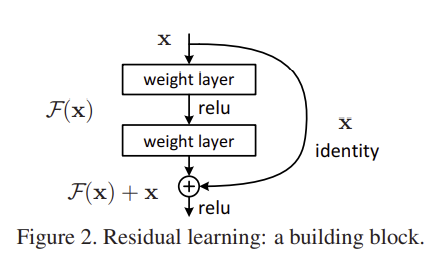
3.1. Residual Learning
- H(x)를 학습하는 것보다 H(x) - x를 학습하는게 더 쉬움.
- 이 아이디어가 왜 나왔나?: 추가된 층이 적어도 “항등 함수”만 학습 해도 얕은 층보다 성능이 떨어지진 않을 텐데, 현재는 층을 쌓을 수록 성능이 떨어짐 -> “항등 함수”조차! 학습 못함..그래서 그냥 잔차 학습! 항등 함수가 최적이면 그냥 잔차를 0으로 보내면 됨.
3.2 Identity Mapping by shortcuts
- Building block
- y = F(x, {Wi}) + x
- x와 F의 차원이 맞지 않은 경우
- y = F(x, {Wi}) + Wsx
- or 그대로 identity mapping 수행하는 대신 제로패딩을 한다.
=> F는 보통 2개 이상의 층을 가짐. 1개의 층을 가지면, 단순 선형함수가 됨.
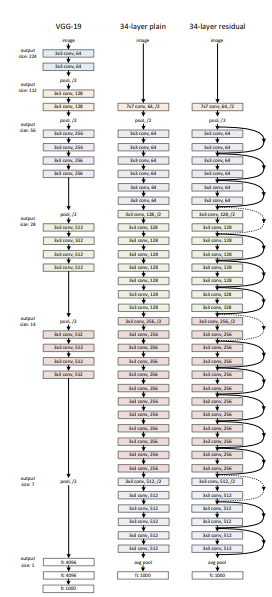
3.3 Network Architectures
3.4 Implementation
train
- scale augmentation: 짧은 변의 길이를 [256, 480] 범위 내에서 임의로 선택하여 리사이즈
- 이후, 리사이즈된 이미지나 그 좌우 반번된 이미지로부터 224x224 크기의 크롭을 무작위로 잘라내고, 각 픽셀에서 평균값을 빼서 정규화.
- Batch Normalization 이용
- 활성화 함수 이용(Relu)
- 최적화: SGD
- mini-batch: 256
- 학습률: 0.1에서 시작 -> 오차가 더 이상 감소하지 않을 때마다 10배씩 줄임.
- 총 학습은 600,000 iteration 동안 진행.
- weight decay는 0.0001
- momentum은 0.9
- dropout은 사용X
test
- 10-crop 평가 방식 이용
- fully-convolutional 형태 채택
- 여러 해상도에서 평균!
- 입력 이미지를 짧은 변의 길이가 {224, 256, 384, 480, 640}이 되도록 리사이즈 하여 결과를 평균
4. Experiments
4.1 ImageNet Classification
- datasets: ImageNet 2012 classification dataset
- train - 1.28 million
- evaluated - 50k
- test - 100k
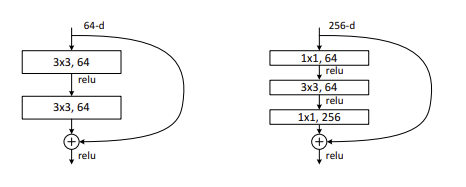
Deeper Bottleneck Architectures
- 계산량을 줄이기 위해 1x1 conv 층을 이용하여 channel의 수만 줄인다.
This post is licensed under CC BY 4.0 by the author.