[cv] openfake_an open dataset and platform toward real World deepfake detection
OpenFake
선행 연구의 한계
- 대부분의 기존 벤치마크들은 오래된 생성 방식에 의존
- DeepFaceLab이나 Face2Face와 같은 GAN 기반 얼굴 교체 도구들이 대표적.
=> 이러한 데이터셋들은 초기 딥페이크 탐지 연구에 유용했지만, 최근의 고품질 합성 미디어―특히 확산(diffusion) 기반 모델과 트랜스포머(transformer) 기반 모델―을 충분히 반영하지 못한다.
- DeepFaceLab이나 Face2Face와 같은 GAN 기반 얼굴 교체 도구들이 대표적.
- 대부분의 데이터셋은 단일 인물 얼굴 이미지(single-face portraits) 에 치중되어 있으며, 실제 세상에서 흔히 접할 수 있는 정치적·사회적 맥락의 합성 이미지―예를 들어 군중 장면, 시위, 재난 이미지, 조작된 표지판, 합성된 스크린샷 등―을 거의 다루지 않는다.
제안
- OPENFAKE2라는 새로운 데이터셋을 제안
- OPENFAKE는 정치적 맥락(politically grounded) 을 반영한 범용 딥페이크 탐지용 데이터셋으로, 대규모의 실제 이미지 코퍼스(real image corpus)를 최신 합성 이미지들과 결합하여 구성
- 이 데이터셋은 OPENFAKE ARENA라는 크라우드소싱 기반 적대적(adversarial) 플랫폼을 통해 지속적으로 확장될 수 있도록 설계되었다. 이 플랫폼은 CLIP 기반의 프롬프트 일관성 검사(prompt-consistency gate) 와 실시간 탐지기(live detector) 를 이용한 점수화 과정을 통해, 검증된 어려운(hard) 샘플들을 지속적으로 수집한다.
이로써 OPENFAKE2는 최신 생성 모델의 진화를 추적할 수 있는 자기 개선형(self-improving) 벤치마크를 제공한다.
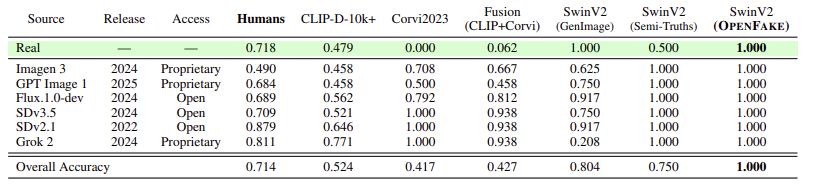
인간 인지 Study
연구 목적
딥페이크 탐지가 얼마나 어려운지를 평가하기 위해, 여러 생성 모델로 만든 합성 이미지에 대한 인간 판별 실험(human study) 을 수행하였다.
실험 설계
- 참가자 수: 100명
- 설문 구성: 참가자마다 무작위로 섞인 24장의 이미지 제시
- 12장: 실제(real) 사진
- 12장: 합성(synthetic) 이미지 (6개 생성모델 × 2장씩)
- 사용된 생성 모델:
- GPT Image 1 (OpenAI, 2025, 상용)
- Imagen 3 (Google, 2024, 상용)
- Grok 2 (xAI, 2024, 상용)
- Flux.1.0-dev (Black Forest Labs, 2024, 오픈소스)
- Stable Diffusion 2.1 (2022, 오픈소스)
- Stable Diffusion 3.5 (2024, 오픈소스)
모든 합성 이미지는 동일한 텍스트 프롬프트로 생성되었으며, 이 프롬프트는 Section 4에서 설명한 자동 추출 파이프라인을 통해 얻어졌다.
→ 즉, 참가자들은 “실제 이미지”와 “같은 문맥에서 생성된 합성 이미지”를 번갈아 보며 판단해야 했다.
총 168장의 고유 이미지가 사용되었으며, 전체 설문, 코드, 이미지 자료는 깃허브 링크 openfake 에 공개되어 있다.
데이터셋 개요 및 수집 과정
- OpenFake = 실제 이미지 저장소 + 최신 생성 모델로 만들어진 고품질 합성 이미지
실제 이미지
- 출처: LAION-400M 데이터셋
- 이 데이터셋은 인터넷에서 수집된 다양한 이미지를 포함하고 있어,실제 허위정보가 유통되는 도메인을 잘 대표한다.
- 또한 이 데이터셋의 많은 이미지들이 합성 이미지 생성 모델의 학습 데이터에도 포함되어 있었을 가능성이 높다.
→ 따라서, 탐지기가 진짜/가짜를 구별하기 더 어렵게 만들어주는 도전적 조건을 제공한다.
- 더불어, 이 이미지들은 현실적 압축 아티팩트(compression artifacts) 를 보존하고 있어 실제 환경(in-the-wild)에서 작동할 탐지기 학습에 매우 중요하다.
- 합성 오염 최소화: LAION 데이터셋의 수집 시기는 2014–2021년, 즉 확산(diffusion) 모델이 공개되기 전(2022) 이므로, 합성 이미지 오염은 극히 적다고 판단.
- 선별 과정: LAION에서 추출한 이미지–캡션 쌍을 Qwen2.5-VL [3] 모델로 필터링하였다. Section C에 제시된 프롬프트 기준에 따라, 이미지가 다음 두 조건 중 하나를 만족할 때만 유지된다.
- 실제 인물의 얼굴(real human faces)을 포함하거나
- 정치적으로 중요하거나 뉴스 가치가 있는 사건을 묘사할 경우
- 프롬프트 생성: 필터링된 각 이미지에 대해 상세한 캡션을 생성하여, 이후 텍스트-이미지 모델의 입력 프롬프트(prompt) 로 사용하였다. → 총 300만 개의 프롬프트가 생성되었으며, 이는 OPENFAKE ARENA의 기본 데이터로 공개됨.
- 품질 제어:
- Qwen2.5-VL을 선택한 이유는 속도와 품질의 균형(trade-off) 때문이다.
- 탐지기가 단순히 저해상도 압축 노이즈로 탐지하는 편법(shortcut) 을 막기 위해, 512×512 픽셀 이하의 이미지는 제외하였다.
- 필터링 및 캡션 생성에 사용된 프롬프트 세부 내용은 Section C, 연산 자원 관련 내용은 Section E에 기술되어 있다.
합성 이미지 (Synthetic Images)
- 생성 모델 목록: OPENFAKE는 아래의 다양한 최신 모델들을 사용해 합성 이미지를 생성하였다.
1
2
3
4
5
6
7
8
9
10
11
12
Stable Diffusion 1.5 / 2.1 / XL / 3.5
Flux 1.0-dev / 1.1-Pro / Schnell
Midjourney v6 / v7
DALL·E 3
Imagen 3 / 4
GPT Image 1
Ideogram 3.0
Grok-2
HiDream-I1
Recraft v3
Chroma
+ Stable Diffusion, Flux의 LoRA·파인튜닝 버전 10종 (커뮤니티 제공)
- 생성 조건:
- 모두 약 1메가픽셀(1MP) 수준의 해상도
- 다양한 비율(9:16, 16:9, 1:1, 2:3, 3:4 등)
- 소셜미디어 포맷과 동일한 형태로 생성
- 라이선스 조건: 일부 상용 모델은 “non-compete(비경쟁)” 조항이 있어, 해당 부분은 비상업적(non-commercial) 라이선스로 공개됨.
데이터 분할 및 접근성
- 테스트 세트 구성:
- 각 생성 모델당 1,000개 이미지를 샘플링 (OOD 모델은 200–600개)
- 동일한 수의 실제 이미지를 매칭
- 총 약 60,000개 이미지 → 전체 데이터의 약 3%
- 나머지는 훈련용(train set)으로 배정
- 균형 유지:
- 테스트 세트 내 모든 모델이 동일한 비율로 포함
- 실제(real) 이미지도 매칭 방식으로 균형화
- 공개 형식:
- 나머지 실제 이미지 및 프롬프트는 CSV 파일로 제공
- 실제 이미지는 원본 URL을 통해 접근 가능
- 모든 자산은 HuggingFace Hub 에 호스팅됨
- 메타데이터:
- 각 이미지에는 프롬프트, 생성 모델명이 함께 포함되어 → 모델 출처(model attribution) 분석이 가능함.
- 지속적 확장: OPENFAKE ARENA를 통해 새로운 합성 이미지가 추가되면, 이에 상응하는 새로운 실제 이미지를 함께 포함시켜 real–synthetic 비율을 지속적으로 균형 유지한다.
크라우드소싱 기반 적대적 플랫폼 (Crowdsourced Adversarial Platform)
생성 모델과 탐지 모델은 함께 진화(co-evolve) 한다. 즉, 더 정교한 생성기(generator) 가 등장하면 더 강력한 탐지기(detector) 가 필요하고, 그에 대응한 새로운 탐지 기술이 발전하면 더 교묘한 생성 모델이 다시 등장한다.
이러한 순환 속에서 벤치마크(benchmark)의 시의성(relevance) 을 유지하기 위해, 우리는 OPENFAKE ARENA를 제안한다.
OPENFAKE ARENA란?
OPENFAKE ARENA는 “딥페이크 탐지기를 속이는 합성 이미지를 직접 만들어보는” 크라우드소싱 기반 대화형 웹 플랫폼이다.
사용자가 실제로 딥페이크 이미지를 생성하여 탐지기를 속이려 시도하고, 성공한 사례가 새로운 데이터로 추가되면서 벤치마크가 스스로 확장·진화하도록 설계되었다.
1
2
3
4
5
6
7
8
9
10
11
flowchart LR
A[🧾 Prompt Bank (3M Prompts)] --> B[👤 User Generates Image]
B --> C[🧠 CLIP-based Prompt Consistency Gate]
C -->|❌ Low similarity| B
C -->|✅ Pass| D[🧩 OPENFAKE Detector Evaluation]
D -->|❌ Detector detects FAKE| E1[⚡ Detector Wins]
D -->|✅ Detector fooled (classified as REAL)| E2[🏅 User Scores Point]
E2 --> F[📈 Image Added to Benchmark]
F --> G[🔁 Detector Periodic Retraining]
G --> H[🧍♂️ Human Review & Quality Validation]
H --> A
기준 탐지기 벤치 마크
이 섹션에서는 OPENFAKE 데이터셋에서 다양한 딥페이크 탐지기(detector) 를 평가한다. 목표는 기존 모델들이 최신 합성 이미지(특히 diffusion·transformer 기반)에도 얼마나 잘 일반화(generalize) 되는지를 측정하는 것이다.
벤치마크 대상 모델들
- SwinV2-Small
- SwinV2-Small은 계층적 비전 트랜스포머(hierarchical vision transformer) 로, 대규모 이미지 분류 작업에서 최신 성능(state-of-the-art) 을 달성한 모델이다.
- 본 연구에서는 SwinV2-Small을 기본 백본(backbone) 으로 사용하여, OPENFAKE 데이터셋으로 직접 학습된 감독(supervised) 탐지기를 구축하였다.
- ConvNeXt baseline
- CNN 계열 최신 아키텍처와의 비교용
- EfficientNet-B4 baseline
- 기존 얼굴 기반 딥페이크 탐지 모델과의 비교를 위해 포함
- CLIP-Based Synthetic Image Detector(준지도 학습)
- CLIP 임베딩 위에 선형 분류기(linear probe) 를 얹어 소량의 학습 데이터만으로 합성 이미지 탐지
- 데이터 효율성 중심 접근법
- InternVL(제로샷)
- 학습(finetuning) 없이 그대로 사용
- 대형 비전–언어 모델(InternVL3-38B)을 활용
- “제로샷” 환경에서의 일반화 성능을 확인
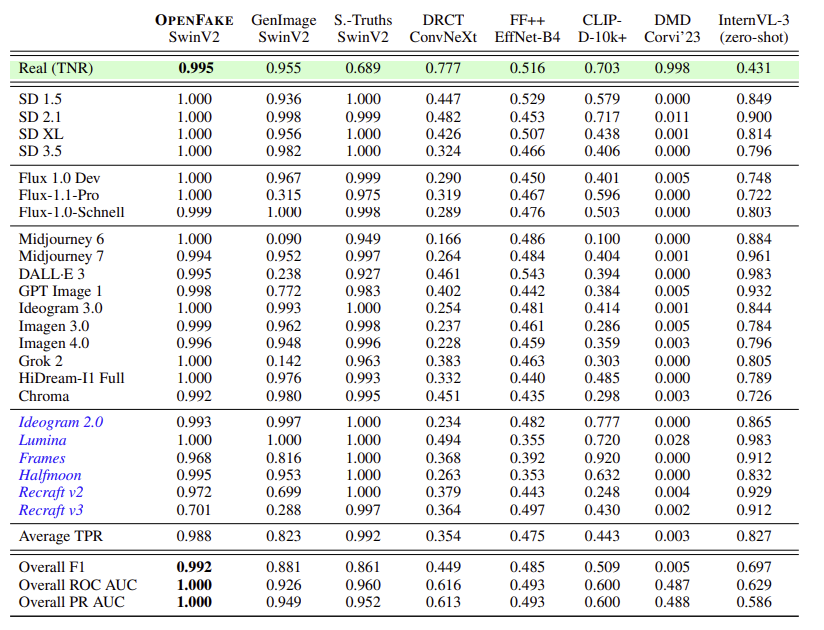
압축 강건성(탐지 모델이 JPEG 등 압축 과정에서 생기는 품질 손실에 얼마나 성능 저하 없이 견디는가?) 평가
- 모델이 압축 아티팩트(compression artifacts) 에 얼마나 강한지를 별도로 평가했다.
- 압축 일치 증강(artifact-matching augmentation) 을 적용했을 때, 동일한 모델은 완전히 압축된 테스트 세트에서도 F1 = 0.992 를 달성했다. (자세한 내용은 Section B.2 참고)
➡️ 즉, 단순히 “깨끗한 이미지”뿐 아니라 SNS 환경에서 흔히 나타나는 압축된(realistic) 이미지에도 매우 견고함을 확인했다.